接上一篇文章 iOS 面试题(一)
题目 9:如何创建一个可以被取消执行的 block?
我们知道 block 默认是不能被取消掉的,请你封装一个可以被取消执行的 block wrapper 类,它的定义如下:
|
|
写法一:创建一个类,将要执行的 block 封装起来,然后类的内部有一个 _isCanceled 变量,在执行的时候,检查这个变量,如果 _isCanceled 被设置成 YES 了,则退出执行。
|
|
另外一种写法,将要执行的 block 直接放到执行队列中,但是让其在执行前检查另一个 isCanceled 的变量,然后把这个变量的修改实现在另一个 block 方法中,如下所示:
|
|
以上两种方法都只能在 block 执行前有效,如果要在 block 执行中有效,只能让 block 在执行中,有一个机制来定期检查外部的变量是否有变化,而要做到这一点,需要改 block 执行中的代码。在本例中,如果 block 执行中的代码是通过参数传递进来的话,似乎并没有什么办法可以修改它了。
题目 10:一个 Objective-C 对象的内存结构是怎样的?
这是一道老题,或许很多人都准备过,其实如果不是被每个公司都考查的话,这道题可以看看候选人对于 iOS 背后底层原理的感兴趣程度。真正对编程感兴趣的同学,都会对这个多少有一些好奇,进而在网上搜索并学习这方面的资料。
以下是本题的简单回答:
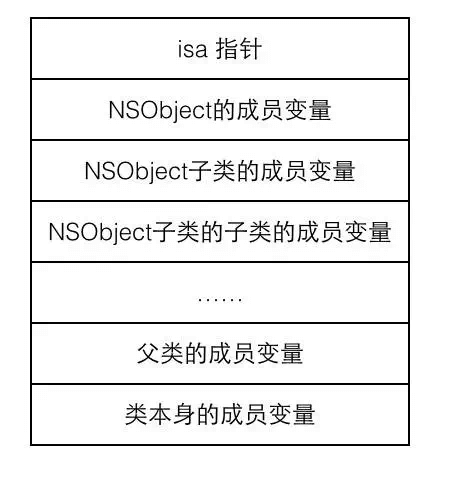
如果把类的实例看成一个C语言的结构体(struct),它首先包含的是一个 isa 指针,而类的其它成员变量依次排列在结构体中。排列顺序如下图所示:
为了验证该说法,我们在Xcode中新建一个工程,在main.m中运行如下代码:
|
|
我们将断点下在 @autoreleasepool 处,然后在Console中输入p *child,则可以看到Xcode输出如下内容,这与我们上面的说法一致。
|
|
因为对象在内存中的排布可以看成一个结构体,该结构体的大小并不能动态变化。所以无法在运行时动态给对象增加成员变量
注:需要特别说明一下,通过 objc_setAssociatedObject 和 objc_getAssociatedObject方法可以变相地给对象增加成员变量,但由于实现机制不一样,所以并不是真正改变了对象的内存结构。
题目 11:Objective-C 对象内存结构中的 isa 指针是用来做什么的,有什么用?
Objective-C 是一门面向对象的编程语言。每一个对象都是一个类的实例。在 Objective-C 语言的内部,每一个对象都有一个名为 isa 的指针,指向该对象的类。每一个类描述了一系列它的实例的特点,包括成员变量的列表,成员函数的列表等。每一个对象都可以接受消息,而对象能够接收的消息列表是保存在它所对应的类中。
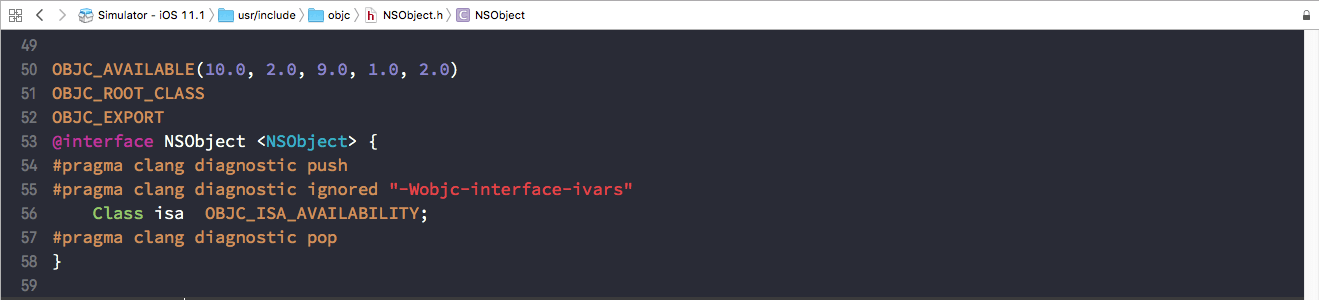
在 Xcode 中按Shift + Command + O, 然后输入 NSObject.h 和 objc.h,可以打开 NSObject 的定义头文件,通过头文件我们可以看到,NSObject 就是一个包含 isa 指针的结构体,如下图所示:
按照面向对象语言的设计原则,所有事物都应该是对象(严格来说 Objective-C 并没有完全做到这一点,因为它有象 int, double 这样的简单变量类型,而 Swift 语言,连 int 变量也是对象)。在 Objective-C 语言中,每一个类实际上也是一个对象。每一个类也有一个名为 isa 的指针。每一个类也可以接受消息,例如代码[NSObject alloc],就是向 NSObject 这个类发送名为alloc消息。
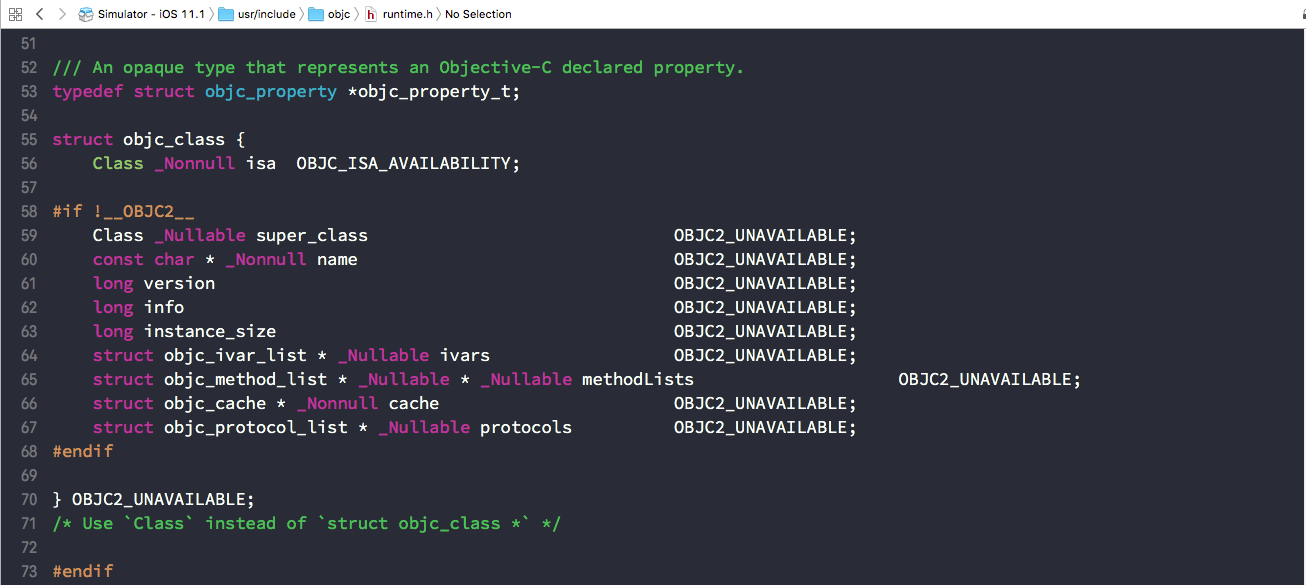
在 Xcode 中按Shift + Command + O, 然后输入 runtime.h,可以打开 Class 的定义头文件,通过头文件我们可以看到,Class 也是一个包含 isa 指针的结构体,如下图所示。(图中除了 isa 外还有其它成员变量,但那是为了兼容非 2.0 版的 Objective-C 的遗留逻辑,大家可以忽略它。)
因为类也是一个对象,那它也必须是另一个类的实列,这个类就是元类 (metaclass)。元类保存了类方法的列表。当一个类方法被调用时,元类会首先查找它本身是否有该类方法的实现,如果没有,则该元类会向它的父类查找该方法,直到一直找到继承链的头。
元类 (metaclass) 也是一个对象,那么元类的 isa 指针又指向哪里呢?为了设计上的完整,所有的元类的 isa 指针都会指向一个根元类 (root metaclass)。根元类 (root metaclass) 本身的 isa 指针指向自己,这样就行成了一个闭环。上面提到,一个对象能够接收的消息列表是保存在它所对应的类中的。在实际编程中,我们几乎不会遇到向元类发消息的情况,那它的 isa 指针在实际上很少用到。不过这么设计保证了面向对象概念在 Objective-C 语言中的完整,即语言中的所有事物都是对象,都有 isa 指针。
我们再来看看继承关系,由于类方法的定义是保存在元类 (metaclass) 中,而方法调用的规则是,如果该类没有一个方法的实现,则向它的父类继续查找。所以,为了保证父类的类方法可以在子类中可以被调用,所以子类的元类会继承父类的元类,换而言之,类对象和元类对象有着同样的继承关系。
我很想把关系说清楚一些,但是这块儿确实有点绕,我们还是来看图吧,很多时候图象比文字表达起来更为直观。下面这张图或许能够让大家对 isa 和继承的关系清楚一些:
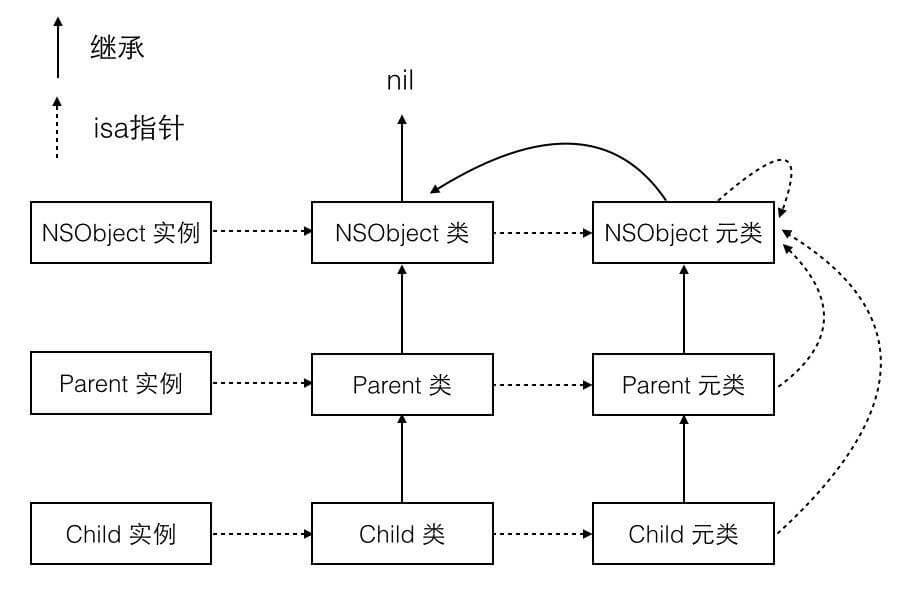
我们可以从图中看出:
- NSObject 的类中定义了实例方法,例如 -(id)init 方法 和 - (void)dealloc 方法。
- NSObject 的元类中定义了类方法,例如 +(id)alloc 方法 和 + (void)load 、+ (void)initialize 方法。
- NSObject 的元类继承自 NSObject 类,所以 NSObject 类是所有类的根,因此 NSObject 中定义的实例方法可以被所有对象调用,例如 - (id)init 方法 和 - (void)dealloc 方法。
- NSObject 的元类的 isa 指向自己。
isa swizzling 的应用
系统提供的 KVO 的实现,就利用了动态地修改 isa 指针的值的技术。在 苹果的文档中可以看到如下描述:
Key-Value Observing Implementation Details
Automatic key-value observing is implemented using a technique called isa-swizzling.
The isa pointer, as the name suggests, points to the object’s class which maintains a dispatch table. This dispatch table essentially contains pointers to the methods the class implements, among other data.
When an observer is registered for an attribute of an object the isa pointer of the observed object is modified, pointing to an intermediate class rather than at the true class. As a result the value of the isa pointer does not necessarily reflect the actual class of the instance.
You should never rely on the isa pointer to determine class membership. Instead, you should use the class method to determine the class of an object instance.
题目 12:给你一棵二叉树,请按层输出其的节点值,即:按从上到下,从左到右的顺序,例如,如果给你如下一棵二叉树:
|
|
输出结果应该是:
|
|
本题的 Swift 代码模版如下:
|
|
本题出自 LeetCode 第 102 题,是一个典型的有关遍历的题目。为了按层遍历,我们需要使用「队列」,来将每一层的节点先保存下来,然后再依次处理。
因为我们不但需要按层来遍历,还需要按层来输出结果,所以我在代码中使用了两个队列,分别名为 level 和 nextLevel,用于保存不同层的节点。
最终,整个算法逻辑是:
- 判断输入参数是否是为空。
- 将根节点加入到队列 level 中。
- 如果 level 不为空,则:
- 将 level 加入到结果 ans 中。
- 遍历 level 的左子节点和右子节点,将其加入到 nextLevel 中。
- 将 nextLevel 赋值给 level,重复第 3 步的判断。
- 将 ans 中的节点换成节点的值,返回结果。
因为我们是用 Swift 来实现代码,所以我使用了一些 Swift 语言的特性。例如:队列中我们保存的是节点的数据结构,但是最终输出的时候,我们需要输出的是值,在代码中,我使用了 Swift 的函数式的链式调用,将嵌套数组中的元素类型做了一次变换,如下所示:
|
|
另外,我们也使用了 Swift 特有的 guard 关键字,来处理参数的特殊情况。完整的参考代码如下:
|
|
题目 13:给你两个链表,分别表示两个非负的整数。每个链表的节点表示一个整数位。为了方便计算,整数的低位在链表头,例如:123 在链表中的表示方式是
|
|
现在给你两个这样结构的链表,请输出它们求和之后的结果。例如:
输入: (2 -> 4 -> 1) + (5 -> 6 -> 1)
输出: 7 -> 0 -> 3
本题的 Swift 代码模版如下:
|
|
这是我高中学习编程时最早接触的一类题目,我们把这类题目叫做「高精度计算」,其实就是在计算机计算精度不够时,模拟我们在纸上演算的方式来计算答案,然后获得足够精度的解。
这道题其实完全不考查什么「算法」,人人都知道怎么计算,但是它考察了「将想法转换成代码」的能力,新手通常犯的毛病就是:意思都明白,但是写不出来代码。所以,这类题目用来过滤菜鸟确实是挺有效的办法。
本题的做法其实没什么特别,就是直接计算。计算的时候需要考虑到以下这些情况:
- 两个整数长度不一致的情况。
- 进位的情况。当进位产生时,我们需要保存一个标志位,以便在计算下一位的和的时候,加上进位。
- 当计算完后,如果还有进位,需要处理最后结果加一位的情况。
以下是完整的代码,我使用了一些 Swift 语言的特性,比如用 flatMap 来减少对于 Optional 类型值为 nil 的判断。
|
|
题目 14:在一个地图中,找出一共有多少个岛屿,我们用一个二维数组表示这个地图,地图中的 1 表示陆地,0 表示水域。一个岛屿是指由上下左右相连的陆地,并且被水域包围的区域
你可以假设地图的四周都是水域。
例一:
|
|
以上地图,一共有 1 个岛屿
|
|
以上地图,一共有 3 个岛屿
我们们可以用一种被称为「种子填充」(floodfill)的办法来解决此题。具体的做法是:
- 遍历整个地图,找到一个未被标记过的,值为 1 的坐标。
- 从这个坐标开始,从上下左右四个方向,标记相邻的 1 。
- 把这些相邻的坐标,都标记下来,递归的进行标记,以便把相邻的相邻块也能标记上。
- 待标记全部完成之后,将岛屿的计数 +1。
- 回到第 1 步。如果第 1 步无法找到未标记的坐标,则结束。
虽然思路简单,但是实现起来代码量也不算小。这里有一些小技巧:
- 我们可以将上下左右四个方向的偏移量保存在数组中,这样在计算位置的时候,写起来更简单一些。
- 递归的标记过程可以用深度优先搜索(DFS)或者宽度优先搜索(BFS)。
以下是完整的参考代码:
以下是完整的参考代码:
|
|
Swift 的参数默认是不能修改值的,但是如果是 C++ 语言的话,我们可以直接在地图上做标记。因为地图只有 0 和 1 两种值,我们可以用 2 表示「标记过的陆地」,这样就省略了额外的标记数组。以下是我写的一个 C++ 的示例程序:
|
|
题目 15:简单介绍 ARC 以及 ARC 实现的原理
ARC 是苹果在 WWDC 2011 提出来的技术,因此很多新入行的同学可能对此技术细节并不熟悉。但是,虽然 ARC 极大地简化了我们的内存管理工作,但是引用计数这种内存管理方案如果不被理解,那么就无法处理好那些棘手的循环引用问题。所以,这道面试题其实是考查同学对于 iOS 程序内存管理的理解深度
自动的引用计数(Automatic Reference Count 简称 ARC),是苹果在 WWDC 2011 年大会上提出的用于内存管理的技术。
引用计数(Reference Count)是一个简单而有效的管理对象生命周期的方式。当我们创建一个新对象的时候,它的引用计数为 1,当有一个新的指针指向这个对象时,我们将其引用计数加 1,当某个指针不再指向这个对象是,我们将其引用计数减 1,当对象的引用计数变为 0 时,说明这个对象不再被任何指针指向了,这个时候我们就可以将对象销毁,回收内存。由于引用计数简单有效,除了 Objective-C 语言外,微软的 COM(Component Object Model )、C++11(C++11 提供了基于引用计数的智能指针 share_prt) 等语言也提供了基于引用计数的内存管理方式。
引用计数这种内存管理方式虽然简单,但是手工写大量的操作引用计数的代码不但繁琐,而且容易被遗漏。于是苹果在 2011 年引入了 ARC。ARC 顾名思义,是自动帮我们填写引用计数代码的一项功能。
ARC 的想法来源于苹果在早期设计 Xcode 的 Analyzer 的时候,发现编译器在编译时可以帮助大家发现很多内存管理中的问题。后来苹果就想,能不能干脆编译器在编译的时候,把内存管理的代码都自动补上,带着这种想法,苹果修改了一些内存管理代码的书写方式(例如引入了 @autoreleasepool 关键字)后,在 Xcode 中实现了这个想法。
ARC 的工作原理大致是这样:当我们编译源码的时候,编译器会分析源码中每个对象的生命周期,然后基于这些对象的生命周期,来添加相应的引用计数操作代码。所以,ARC 是工作在编译期的一种技术方案,这样的好处是:
- 编译之后,ARC 与非 ARC 代码是没有什么差别的,所以二者可以在源码中共存。实际上,你可以通过编译参数 -fno-objc-arc 来关闭部分源代码的 ARC 特性。
- 相对于垃圾回收这类内存管理方案,ARC 不会带来运行时的额外开销,所以对于应用的运行效率不会有影响。相反,由于 ARC 能够深度分析每一个对象的生命周期,它能够做到比人工管理引用计数更加高效。例如在一个函数中,对一个对象刚开始有一个引用计数 +1 的操作,之后又紧接着有一个 -1 的操作,那么编译器就可以把这两个操作都优化掉。
但是也有人认为,ARC 也附带有运行期的一些机制来使 ARC 能够更好的工作,他们主要是指 weak 关键字。weak 变量能够在引用计数为 0 时被自动设置成 nil,显然是有运行时逻辑在工作的。我通常并没有把这个算在 ARC 的概念当中,当然,这更多是一个概念或定义上的分歧,因为除开 weak 逻辑之外,ARC 核心的代码都是在编译期填充的。
题目 16:Android 手机通常使用 Java 来开发,而 Java 是使用垃圾回收这种内存管理方式。 那么,ARC 和垃圾回收对比,有什么优点和缺点?
此题其实是考查大家的知识面,虽然做 iOS 开发并不需要用到垃圾回收这种内存管理机制。但是垃圾回收被使用得非常普遍,不但有 Java,还包括 JavaScript, C#,Go 等语言
作为 iOS 开发者,了解一下这个世界上除了 ARC 之外最流行的内存管理方式,还是挺有价值的。所以我尽量简单给大家介绍一下。
垃圾回收(Garbage Collection,简称 GC)这种内存管理机制最早由图灵奖获得者 John McCarthy 在 1959 年提出,垃圾回收的理论主要基于一个事实:大部分的对象的生命期都很短。
所以,GC 将内存中的对象主要分成两个区域:Young 区和 Old 区。对象先在 Young 区被创建,然后如果经过一段时间还存活着,则被移动到 Old 区。(其实还有一个 Perm 区,但是内存回收算法通常不涉及这个区域)
Young 区和 Old 区因为对象的特点不一样,所以采用了两种完全不同的内存回收算法。
Young 区的对象因为大部分生命期都很短,每次回收之后只有少部分能够存活,所以采用的算法叫 Copying 算法,简单说来就是直接把活着的对象复制到另一个地方。Young 区内部又分成了三块区域:Eden 区 , From 区 , To 区。每次执行 Copying 算法时,即将存活的对象从 Eden 区和 From 区复制到 To 区,然后交换 From 区和 To 区的名字(即 From 区变成 To 区,To 区变成 From 区)。
Old 区的对象因为都是存活下来的老司机了,所以如果用 Copying 算法的话,很可能 90% 的对象都得复制一遍了,不划算啊!所以 Old 区的回收算法叫 Mark-Sweep 算法。简单来说,就是只是把不用的对象先标记(Mark)出来,然后回收(Sweep),活着的对象就不动它了。因为大部分对象都活着,所以回收下来的对象并不多。但是这个算法会有一个问题:它会产生内存碎片,所以它一般还会带有整理内存碎片的逻辑,在算法中叫做 Compact。如何整理呢?早年用过 Windows 的硬盘碎片整理程序的朋友可能能理解,其实就是把对象插到这些空的位置里。这里面还涉及很多优化的细节,我就不一一展开了。
讲完主要的算法,接下来 GC 需要解决的问题就只剩下如何找出需要回收的垃圾对象了。为了避免 ARC 解决不了的循环引用问题,GC 引入了一个叫做「可达性」的概念,应用这个概念,即使是有循环引用的垃圾对象,也可以被回收掉。下面就给大家介绍一下这个概念。
当 GC 工作时,GC 认为当前的一些对象是有效的,这些对象包括:全局变量,栈里面的变量等,然后 GC 从这些变量出发,去标记这些变量「可达」的其它变量,这个标记是一个递归的过程,最后就像从树根的内存对象开始,把所有的树枝和树叶都记成可达的了。那除了这些「可达」的变量,别的变量就都需要被回收了。
听起来很牛逼对不对?那为什么苹果不用呢?实际上苹果在 OS X 10.5 的时候还真用了,不过在 10.7 的时候把 GC 换成了 ARC。那么,GC 有什么问题让苹果不能忍,这就是:垃圾回收的时候,整个程序需要暂停,英文把这个过程叫做:Stop the World。所以说,你知道 Android 手机有时候为什么会卡吧,GC 就相当于春运的最后一天返城高峰。当所有的对象都需要一起回收时,那种体验肯定是当时还在世的乔布斯忍受不了的。
看看下面这幅漫画,真实地展现出 GC 最尴尬的情况(漫画中提到的 Full GC,就是指执行 Old 区的内存回收):

ARC 相对于 GC 的优点:
- ARC 工作在编译期,在运行时没有额外开销。
- ARC 的内存回收是平稳进行的,对象不被使用时会立即被回收。而 GC 的内存回收是一阵一阵的,回收时需要暂停程序,会有一定的卡顿。
ARC 相对于 GC 的缺点:
- GC 真的是太简单了,基本上完全不用处理内存管理问题,而 ARC 还是需要处理类似循环引用这种内存管理问题。
- GC 一类的语言相对来说学习起来更简单。
总结的唐巧的面试题就这些了,建议关注他本人的微信号,每篇面试题下面的评论也能让你受益不少!
以上です